우리는 이제 API도 다룰 수 있는 프로그래머다.
그런데 API를 통해 나온 결과를 매번 하나씩 확인해서 봐야할까?
저장하거나 다른 파일에 저장되어 있는 목록으로 API와 연동하려면 어떻게 해야할까?
이 질문에 대한 해결방법으로 2가지 방법을 진행할 예정인데,
첫번째는 텍스트파일(txt)이며, 다음 시간에 다룰 두번째는 엑셀(excel) 이다.
1. 텍스트파일(.txt) 다루기
- 일반적으로 우리가 사용하는 텍스트 파일의 기능은 크게 2가지(+1가지)로 구분할 수 있는데, 쓰기와 읽기이다.
(+1로 표현한 내용은 내용 추가인데 쓰기의 연장이라 크게 어려울 것이 없다.)
2. 텍스트 파일 쓰기(만들기)
#텍스트 파일 만들기
create_text = open('./text_test.txt','w', encoding='utf-8')
create_text.write('안녕하세요.')
create_text.write('오늘도 공부하는')
create_text.write('올라운더입니다.\n')
create_text.write('모두들 힘내세요.\n')
create_text.close()
- 2라인에서 텍스트 파일의 객체를 생성해주는데, open 뒤에 입력 되는 각각의 파라미터는 경로, 동작(쓰기), 인코딩 정보를 입력한다.
주의 사항으로
1) 경로를 입력할 때에는 역슬러쉬(\)의 경우 탈출문자로 인식되므로 일반적인 슬러쉬(/) 또는 f string을 이용한다.
2) 경로의 온점(.)은 현재 폴더를 나타낼 때 사용하는 상대경로이다.
3) 'w'는 쓰기 모드를 나타내며
4) 인코딩의 경우 사람이 볼 때에는 똑같은 문자라도 컴퓨터는 다른 문자로 인식할 수 있는데 이를 지정해주는 방식이다. 일반적으로 한글과 영어를 사용할 때에는 utf-8을 사용한다.
- 4~7라인을 보면 생성된 create_text 객체의 write 함수를 이용하여 문자열을 입력하는데, 결과 파일을 보면 write는 기본 값으로 줄바꿈(Enter, \n)가 입력되어 있지 않는 것을 알 수 있다.
- 9 라인과 같이 open 을 사용할 경우 close를 꼭 실행해주어야한다. 쓰기 모드로 열린 텍스트 파일 객체를 close를 하지 않으면 해당 객체를 재사용할 때 에러가 발생한다.
- 해당 방법을 사용하지 않고 with 문을 이용하여 작성도 가능하다. 이때에는 close는 생략된다.
with을 사용할 경우, 처리될 코드에 대해 들여쓰기가 필요하며 위의 결과와 동일하게 작성되는 것을 알 수 있다.
#텍스트 파일 만들기2
with open('./text_test2.txt','w', encoding='utf-8') as f:
f.write('안녕하세요.')
f.write('오늘도 공부하는')
f.write('올라운더입니다.\n')
f.write('모두들 힘내세요.\n')
3. 텍스트 파일 쓰기2(내용 추가)
- 위에서 사용한 open 함수의 'w' 쓰기 모드 일 경우, 기존 내용이 있더라도 해당 내용을 초기화 한 후 작성한다.
- 그래서 기존의 내용에 내용을 추가하기 위해서는 'w'가 아닌 'a'를 이용하여 내용을 추가할 수 있다.
#텍스트 파일 만들기2
with open('./text_test2.txt','a', encoding='utf-8') as f:
f.write('내일은 더 좋은 날이 될 거에요.')
- 위의 결과 값과 같이 기존의 내용에 내용이 추가 된 것을 확인할 수 있다.
4. 텍스트 파일 읽기
- 이제 작성한 파일 또는 기존의 작성된 파일을 읽어볼 차례이다.
#텍스트 읽기 read
with open('./text_test2.txt','r', encoding='utf-8') as f:
a = f.read()
print('read로 결과 값 출력 : ')
print(a)
print('\n')
#텍스트 읽기 readline
with open('./text_test2.txt','r', encoding='utf-8') as f:
b = f.readline()
print('readline로 결과 값 출력 : ')
print(b)
print('\n')
#텍스트 읽기 readlines
with open('./text_test2.txt','r', encoding='utf-8') as f:
c = f.readlines()
print('readlines로 결과 값 출력 : ')
print(c)
print('\n')
- 파일을 읽을 때에는 사용하는 매서드에 따라 결과 값이 다르게 나타나는데,
1) read 는 입력되어 있는 텍스트 전체를 하나의 객체로 읽어와 출력을 하고
2) readline는 한줄씩 읽어와서 출력이 된다. 현재는 텍스트 파일의 1번째줄을 읽었기 때문에 1번째 줄만 출력하고 함수는 종료된다.
3) readlines는 전체를 읽어오되 리스트의 자료형으로 각각의 줄바뀜 기호에 맞게 불러오게 된다.
* 사용목적에 맞게 해당 내용을 사용할 수 있다.
5. 코드 함수화 하기
- 이전에 작성된 파파고 번역 코드를 함수로 변경하고 입력되어 있는 텍스트와 연계시켜 보려한다.
- 먼저 기존 코드를 함수로 바꾸되, 번역할 내용을 파라미터로 전달 받는다.
import os
import sys
import urllib.request
import naver_trans_api_token as ntoken # 네이버 API 계정 정보
from ast import literal_eval # str to dict
def papago_call(source_text):
#client_id = "YOUR_CLIENT_ID" # 개발자센터에서 발급받은 Client ID 값
client_id = ntoken.naver_trans_api_token['client_id']
#client_secret = "YOUR_CLIENT_SECRET" # 개발자센터에서 발급받은 Client Secret 값
client_secret = ntoken.naver_trans_api_token['client_secret']
encText = urllib.parse.quote(source_text) # 번역하고자 하는 문장 입력
data = "source=ko&target=en&text=" + encText # 한국어 -> 영어 로 변환
url = "https://openapi.naver.com/v1/papago/n2mt"
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request, data=data.encode("utf-8"))
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
response_result = response_body.decode('utf-8')
res_result_to_dict= literal_eval(response_result)
print(type(res_result_to_dict)) # 결과 값 : dict
print(res_result_to_dict)
print('\n\n번역 내용 :')
print(res_result_to_dict['message']['result']['translatedText']) # 결과 값 : Hello
else:
print("Error Code:" + rescode)
papago_call('곰 세마리가 한집에 있어')
- papago_call 함수를 만들고 파라미터로 번역할 텍스트를 전달 받는다.
6. 텍스트 파일 읽어온 뒤 해당 내용 번역하기
- 아까 생성했던 파일을 이용하거나 다른 원하는 텍스트를 파일로 저장한다.
import os
import sys
import urllib.request
import naver_trans_api_token as ntoken # 네이버 API 계정 정보
from ast import literal_eval # str to dict
def papago_call(source_text):
#client_id = "YOUR_CLIENT_ID" # 개발자센터에서 발급받은 Client ID 값
client_id = ntoken.naver_trans_api_token['client_id']
#client_secret = "YOUR_CLIENT_SECRET" # 개발자센터에서 발급받은 Client Secret 값
client_secret = ntoken.naver_trans_api_token['client_secret']
encText = urllib.parse.quote(source_text) # 번역하고자 하는 문장 입력
data = "source=ko&target=en&text=" + encText # 한국어 -> 영어 로 변환
url = "https://openapi.naver.com/v1/papago/n2mt"
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request, data=data.encode("utf-8"))
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
response_result = response_body.decode('utf-8')
res_result_to_dict= literal_eval(response_result)
# print(type(res_result_to_dict)) # 결과 값 : dict
# print(res_result_to_dict)
# print('\n\n번역 내용 :')
result = res_result_to_dict['message']['result']['translatedText']
print(result) # 결과 값 : Hello
return result
else:
print("Error Code:" + rescode)
# 텍스트 파일 생성하기
with open('./bear_family.txt','w', encoding='utf-8') as f:
f.write('곰 세마리가 한 집에 있어.\n')
f.write('아빠곰, 엄마곰, 아기곰\n')
f.write('아빠곰은 뚱뚱해\n')
f.write('엄마곰은 날씬해.\n')
f.write('아기곰은 너무 귀여워\n')
f.write('으쓱 으쓱 잘한다.\n')
# 텍스트 파일 읽기(readlines)
with open('./bear_family.txt','r', encoding='utf-8') as f:
text_readlines = f.readlines()
# 텍스트를 반복문을 이용하여 실행(실행된 결과 기존 텍스트 파일에 추가하기)
for trans_source in text_readlines:
trans_result = papago_call(trans_source)
with open('./bear_family.txt','a', encoding='utf-8') as f:
f.write(trans_result+'\n')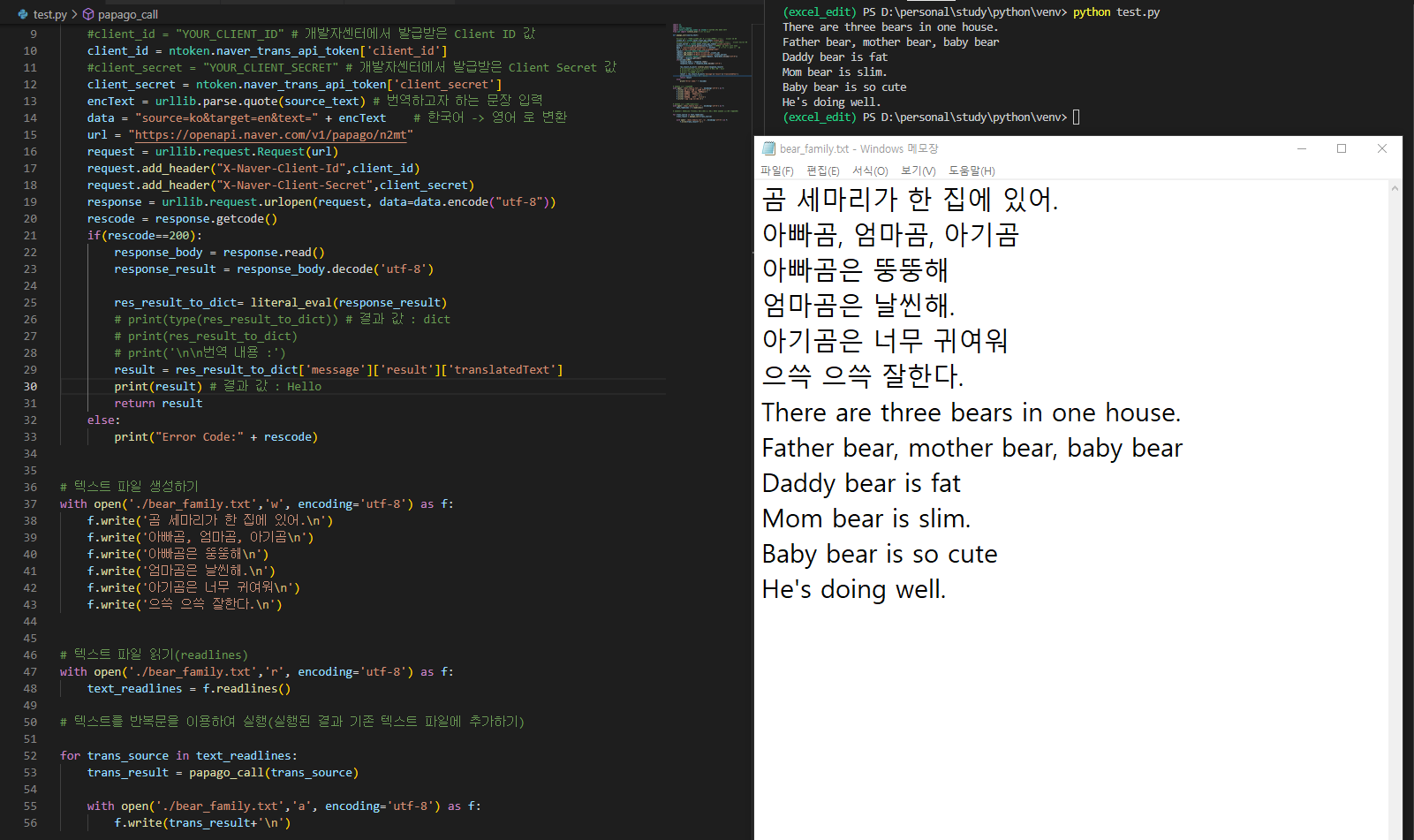
- 파일을 한글로 쓰고, readlines로 읽고 반복문과 파파고 API 호출문을 이용하여 결과 값을 얻고, 해당 내용을 다시 파일에 추가하는 일련의 과정이 담겨있다.(오늘 진행한 과정이 모두 담겨 있다.)
- 먼저 papago_call 함수의 번역 결과를 result 객체에 담고(29라인), return을 이용하여 결과를 전달(31라인)하도록 수정했다.
- 37~43 라인을 통해 한글로 텍스트 파일을 생성한 뒤,
- 47~48 라인의 readlines를 통해 번역 할 한글의 목록(리스트)를 만들었다.
- 52라인 : for 반복문을 통해 48라인에서 생성된 각각의 요소를 순서대로 뽑아서
- 53라인 : 번역을 진행했고, 번역된 영문을 trans_result 객체에 저장한다.
- 55~56 라인 : 한글 원본이 있는 텍스트 파일에 추가 모드(a)로 실행하여 53라인에서 생성된 영문 내용을 추가한다.
- 해당 경로의 결과 파일을 확인해보면 정상적으로 번역되어 있는 결과를 확인할 수 있다.
어떠신가요? 이제 파일도 마음대로 다룰 수 있는 진짜 개발자가 된 것 같으신가요?
이제 다음시간은 파이썬에서 엑셀을 이용하는 방법을 알아보겠습니다.
'Python' 카테고리의 다른 글
| 22. 파이썬 엑셀(Excel) 다루기2 - openpyxl (0) | 2023.07.25 |
|---|---|
| 22. 파이썬 엑셀(Excel) 다루기1 - openpyxl (0) | 2023.07.22 |
| 20. 파이썬 네이버 API(Papago) 연동하기1 (0) | 2023.07.18 |
| 19. 파이썬 API 연동하기 (0) | 2023.07.12 |
| 18. 파이썬 클래스2(class) (0) | 2023.07.11 |



