지난 시간까지 기본적인 파일 생성 후, sheet를 다루는 방법에 대해 알아 보았다.
그러나 엑셀을 직접 생성할 때도 있지만 생성된 엑셀을 수정하거나 데이터를 확인하는 작업도 필요할 것이다.
이때에는 해당 파일에 대한 Workbook과 Worksheet를 불러오면 되는데 방법은 아래와 같다.
0. 엑셀(Excel) 파일 불러오기
- openpyxl 에서 다른 Excel 파일을 불러오기 위해서는 load_workbook 메서드가 필요하다.
from openpyxl import load_workbook #excel 파일 load를 위한 import
# wb 객체 만들기(path+file_name)
wb = load_workbook('./excel_prac1.xlsx')
print('- 전체 sheet 명 출력 : ')
sheets_name = wb.sheetnames
print(sheets_name)
- 지난 포스팅에서 작성한 excel_prac1.xlsx 파일을 불러 온뒤 sheet 들을 확인해보면 우리가 생성했던 sheet들을 통해 정상적으로 wb을 불러 왔음을 확인할 수 있다.
- 4라인을 보면 파라미터로 해당 파일의 경로와 파일명을 입력하게 되는데, 같은 경로일 경우에는 '.'을 입력하여 단순히 표기할 수도 있고, 아래와 같이 절대경로를 입력해줄 수도있다.
- 7라인을 보게되면 경로에 대한 정상적인 출력을 위해 r string을 사용하였다. 일반적인 포멧의 string을 사용할 경우 역슬러쉬('\')로 인해 탈출문자가 적용되므로,
1) r string 또는 f string 사용
2) 슬러쉬('/') 사용
3) 탈출문자를 고려한 경로 입력('\\') 의 방법이 있으나, 1, 2번의 방법 중 선택하면 효율적으로 코딩을 진행할 수 있다.
from openpyxl import load_workbook #excel 파일 load를 위한 import
# wb 객체 만들기(path+file_name)
#wb = load_workbook('./excel_prac1.xlsx')
# 절대 경로를 이용한 wb 객체 만들기(path+file_name)
file_path = r'D:\personal\study\python\venv'
file_name = '\excel_prac1.xlsx'
wb = load_workbook(file_path+file_name)
print('- 전체 sheet 명 출력 : ')
sheets_name = wb.sheetnames
print(sheets_name)
- 물론 load_workbook 메소드에도 적용할 수 있는 option 파라미터들이 존재하는데,
filename(필수), read_only, Keep_vba, data_only, keep_links 이다.
- 우리가 사용한 filename의 경우 필수로 입력되어야 하나, 나머지 값들은 입력되지 않을 경우, False(미사용)을 기본 값으로 적용하게된다.
1) read_only(기본 값 False) : 읽기 모드(파일 수정 불가)
2) keep_vba(기본 값 False) : 엑셀에 적용되어 있는 vba(비쥬얼베이직) 기능을 가져 올 것인지 설정
3) data_only(기본 값 False) : 엑셀에서 해당 셀에 수식이 적용되어 있을 경우, 적용된 수식을 가져 올 것 인지(False), 수식이 적용된 결과 값을 가져 올 것인지(True) 설정
4) keep_links(기본 값 False) : 엑셀 파일안에 있는 링크를 사용할 것인지 설정
from openpyxl import load_workbook #excel 파일 load를 위한 import
# 절대 경로를 이용한 wb 객체 만들기(path+file_name)
file_path = r'D:\personal\study\python\venv'
file_name = '\load_parameter(data).xlsx'
# data_only 파라미터 미적용(False)
wb1 = load_workbook(file_path+file_name, data_only=False)
ws1 = wb1['Sheet1']
print(ws1['B4'].value) # 결과 값 : =sum(B2:B3)
# data_only 파라미터 적용(True)
wb2 = load_workbook(file_path+file_name, data_only=True)
ws2 = wb2['Sheet1']
print(ws2['B4'].value) # 결과 값 : 170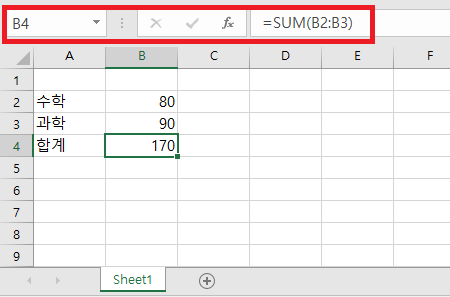
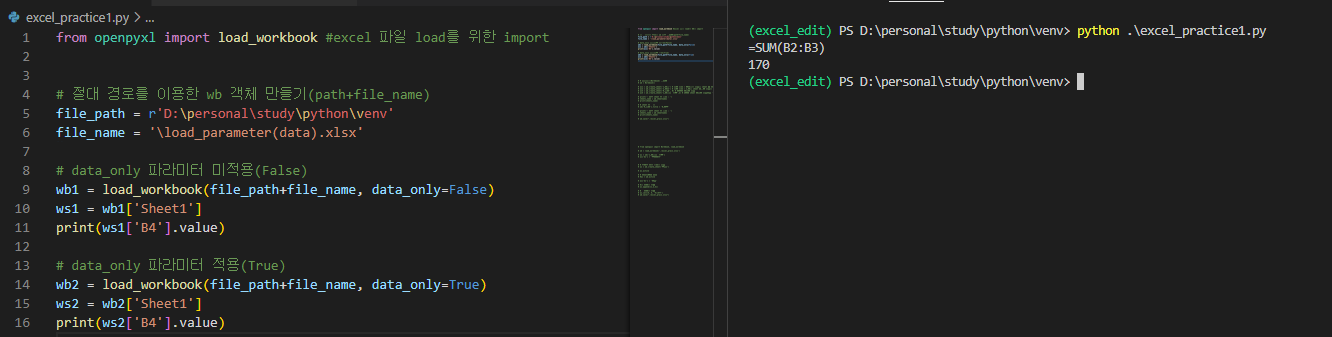
- 간단히 B4 셀에 수학점수와 과학점수를 합한 수식이 입력된 엑셀 파일을 data_only 파라미터의 적용에 따라 불러오게 되면 해당 셀의 값이 '=SUM(B2:B3)' 와 '170' 으로 다르게 표기됨을 확인할 수 있다.
이제 실제 데이터를 cell 단위로 입력하거나 다루는 방법을 확인해보겠다.
1. column과 row
- 엑셀(Excel)은 기본적으로 가로축인 column(알파벳열)과 세로축인 row(숫자행)의 조합된 영역을 통해 표기된다.
- openpyxl에서도 이를 이용하여 해당 셀(cell)의 값을 입력하거나 읽어 올 수가 있다.
1) cell 값 입력하기
- cell 값을 입력하는 방법은 2가지가 있는데, 문자열과 숫자행을 조합하여 입력하는 방법(10~13라인)과 해당 셀의 column 값과 row 값을 지정하여 입력하는 방법이다.
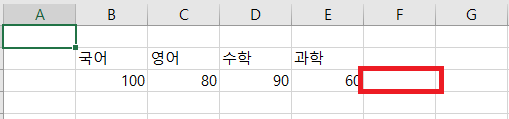
- 아래의 이미지를 보게 되면 90점이라는 수학 점수를 나타내는 방법은 'D3' 라는 빨간색 영역을 통해 표시할 수도 있지만, 문자열에도 숫자를 부여하여 column 순서(초록색)와 row 순서(보라색)을 이용해 해당 위치를 찾을 수도 있다.
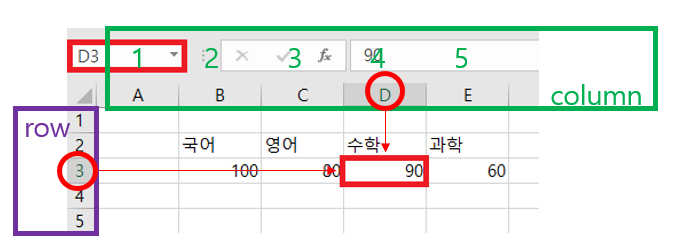
- 아래 코드는 위의 2가지 방법을 입력하는 과정이며, 실제 대량의 데이터를 입력하거나 다룰 때에는 pandas라는 별도의 라이브러리를 사용하나, 이번 포스팅은 openpyxl에 관한 과정이므로 반복문을 사용하는 방법으로 다루게된다.
(*위에 언급한 대로 Excel에 대량의 데이터를 입력하거나 처리할 때에는 openpyxl과 pandas 2가지 라이브러리를 혼합하여 작성하는 것이 효율적이다.)
from openpyxl import Workbook, load_workbook #excel 파일 load를 위한 import
# 통합문서(Workbook) 만들기
wb = Workbook()
sheets_name = wb.sheetnames[0]
ws = wb[sheets_name]
# 해당 셀에 직접 입력하기
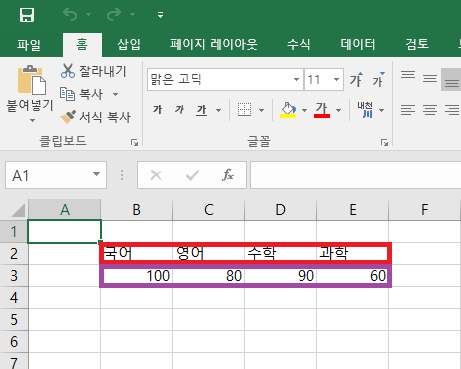
ws['B2'] = '국어'
ws['C2'] = '영어'
ws['D2'] = '수학'
ws['E2'] = '과학'
# cell 위치에 반복문을 통한 입력
student1_score = [100, 80, 90, 60]
for idx, score in enumerate(student1_score):
ws.cell(column=2+idx, row=3).value = score
wb.save("./excel_prac2.xlsx")
- 6라인을 보게되면 wb.sheetnames의 경우 해당 Workbook의 sheet 명을 리스트 형태로 반환해주는 메서드이다. 우리는 기본으로 생성할 때 'Sheet'라는 이름의 Sheet 가 생성됨을 지난 포스팅을 통해 알고 있지만 그런 복잡한 과정이나 sheet명이 잘못 입력되어 발생하는 오류를 제거하기 위해 해당 리스트의 첫번째 값([0])을 통해 sheet명을 입력 받는다.
- 18 라인의 경우 for 반복문과 함께 자주 사용하게 되는 enumerate 함수는 대상 리스트 또는 튜플의 인덱스 값과 실제 값을 반환해주는 함수로 for 반복문을 사용할 때에 별도의 인덱스 변수나 카운트 변수를 생성해주지 않아도 자동으로 생성할 수 있는 유용한 방법이며, enumerate로 할당 되는 인덱스 값은 기본 값으로 0부터 시작하나, 'student1_score, 1' 처럼 2번째 파라미터를 입력하게 되면 해당 값 부터 시작하게 된다.
- 따라서 위의 18라인의 enumerate 값을 기준으로 19라인의 입력 값은 B열(column = 2)에 인덱스 값을 추가하여 우측으로 이동하며 입력하게 된다.(row는 한 학생의 점수이므로 3열이 고정되어 있으나, 유사한 방법으로 이동할 수 있다.)
2) cell 값 읽어오기 (확인하기)
- 우리는 해당 셀에 값을 입력하기 위해 위에서 2가지 방법으로 입력할 수 있다는 것을 배웠는데, 값을 읽을 때에도 그대로 적용하여 사용할 수 있다. 해당 셀에 접근한 뒤, .value 로 해당 셀의 변수 값을 불러오면 된다.
(*위의 load_workbook의 파라미터 적용 예문에서 확인했듯이, data_only 파라미터 적용 여부에 따라 value 값은 다르게 나타날 수 있다.)
from openpyxl import Workbook, load_workbook #excel 파일 load를 위한 import
# 통합문서(Workbook) 만들기
wb = Workbook()
sheets_name = wb.sheetnames[0]
ws = wb[sheets_name]
# 해당 셀에 직접 입력하기
ws['B2'] = '국어'
ws['C2'] = '영어'
ws['D2'] = '수학'
ws['E2'] = '과학'
# cell 위치에 반복문을 통한 입력
student1_score = [100, 80, 90, 60]
for idx, score in enumerate(student1_score):
ws.cell(column=2+idx, row=3).value = score
wb.save("./excel_prac2.xlsx")
# 위에서 생성된 통합문서 불러온 뒤, 점수 불러오기
wb = load_workbook("./excel_prac2.xlsx")
sheets_name = wb.sheetnames[0]
ws = wb[sheets_name]
# 방법 1, 문자열+행(row)번호
print('방법 1, 문자열+행번호 이용: ')
print(ws['B2'].value)
print(ws['C2'].value)
print(ws['D2'].value)
print(ws['E2'].value)
#방법 2, 열(column) 번호+ 행(row)번호
print('방법 2, 열(column) 번호+ 행(row)번호 이용 : ')
for score_idx in range(1,6): # value 값 빈 칸일 때 확인을 위해 6으로 적용
cell_value = ws.cell(column=1+score_idx, row = 3).value
print(cell_value)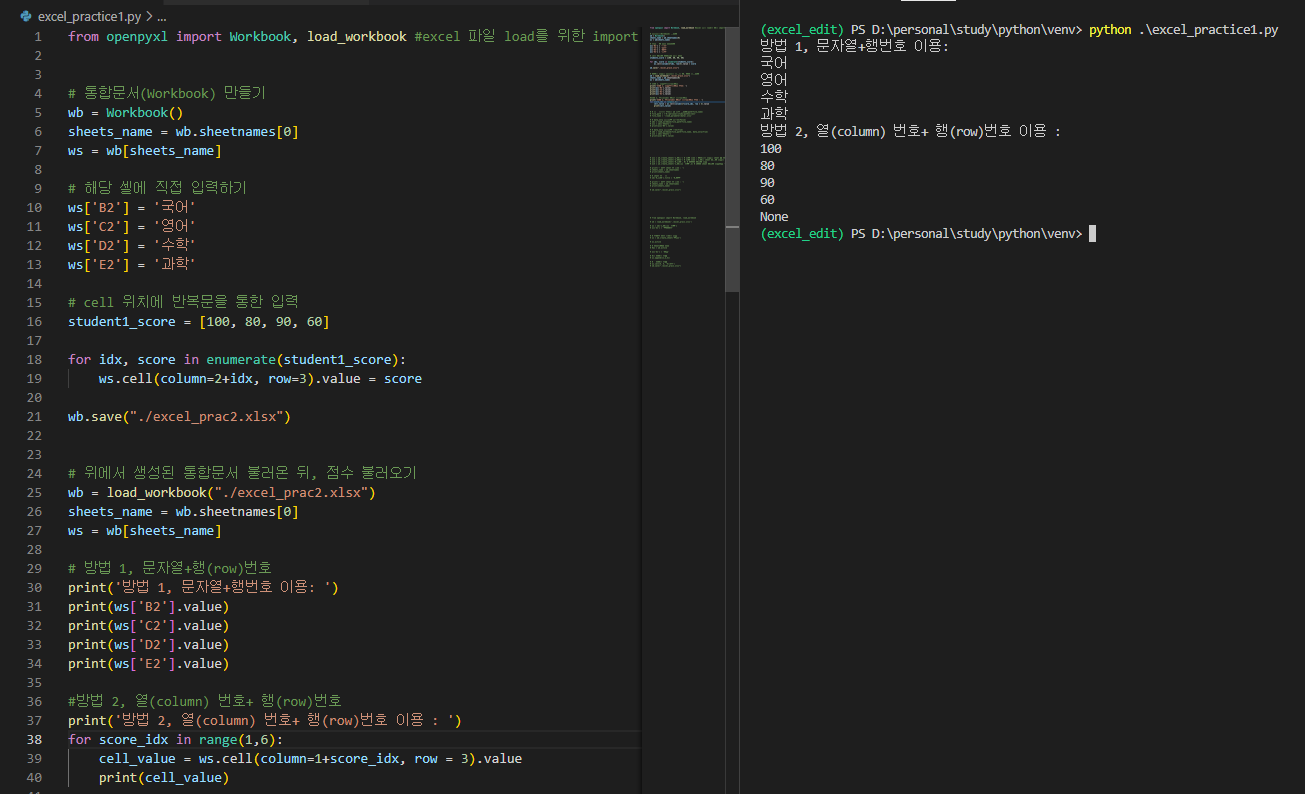
- 문자열+행번호(방법1) 을 이용하던지 열번호+행번호(방법2) 를 이용하던지 상관없이 해당 셀에 접근한뒤 value 라는 변수를 호출해주면 해당 값을 확인할 수 있다.
- 38라인을 보면 열번호를 6으로 설정하였는데, 해당 값으로 설정한 이유는 값이 없을 때 출력하는 None을 확인하기 위해서 이다.

- None과 0은 다르다. 0은 실제 해당 값이 0인것이지만 None은 입력 자체가 안된 값을 나타내기 때문이다.
- None이라는 값을 이용해 다음 행에 내용을 추가할 수도 있는데 자세한 내용은 3)에서 다뤄보자.
3) row max 값 확인 후 입력하기 또는 데이터 전체 불러오기
- 엑셀의 경우 기존 데이터에 내용을 추가하는 경우가 빈번히 발생한다. 눈으로 볼 때에는 마지막 행을 확인한 후 값을 입력하면 되지만, openpyxl에서는 어떻게 입력할 수 있을까?
- 해당 문제를 해결하기 위해서는 해당 셀에 값이 없을 때 위에서 배운 대로 None이 출력된다는 것을 이용해볼 수 있다.
from openpyxl import Workbook, load_workbook #excel 파일 load를 위한 import
# 통합문서(Workbook) 만들기
wb = Workbook()
sheets_name = wb.sheetnames[0]
ws = wb[sheets_name]
# 해당 셀에 직접 입력하기
ws['B2'] = '국어'
ws['C2'] = '영어'
ws['D2'] = '수학'
ws['E2'] = '과학'
# cell 위치에 반복문을 통한 입력
student1_score = [100, 80, 90, 60]
for idx, score in enumerate(student1_score):
ws.cell(column=2+idx, row=3).value = score
wb.save("./excel_prac2.xlsx")
# 위에서 생성된 통합문서 불러온 뒤, 점수 불러오기
wb = load_workbook("./excel_prac2.xlsx")
sheets_name = wb.sheetnames[0]
ws = wb[sheets_name]
# 방법 1, 문자열+행(row)번호
print('방법 1, 문자열+행번호 이용: ')
print(ws['B2'].value)
print(ws['C2'].value)
print(ws['D2'].value)
print(ws['E2'].value)
#방법 2, 열(column) 번호+ 행(row)번호
print('방법 2, 열(column) 번호+ 행(row)번호 이용 : ')
for score_idx in range(1,6):
cell_value = ws.cell(column=1+score_idx, row = 3).value
print(cell_value, end= ': ')
print(type(cell_value))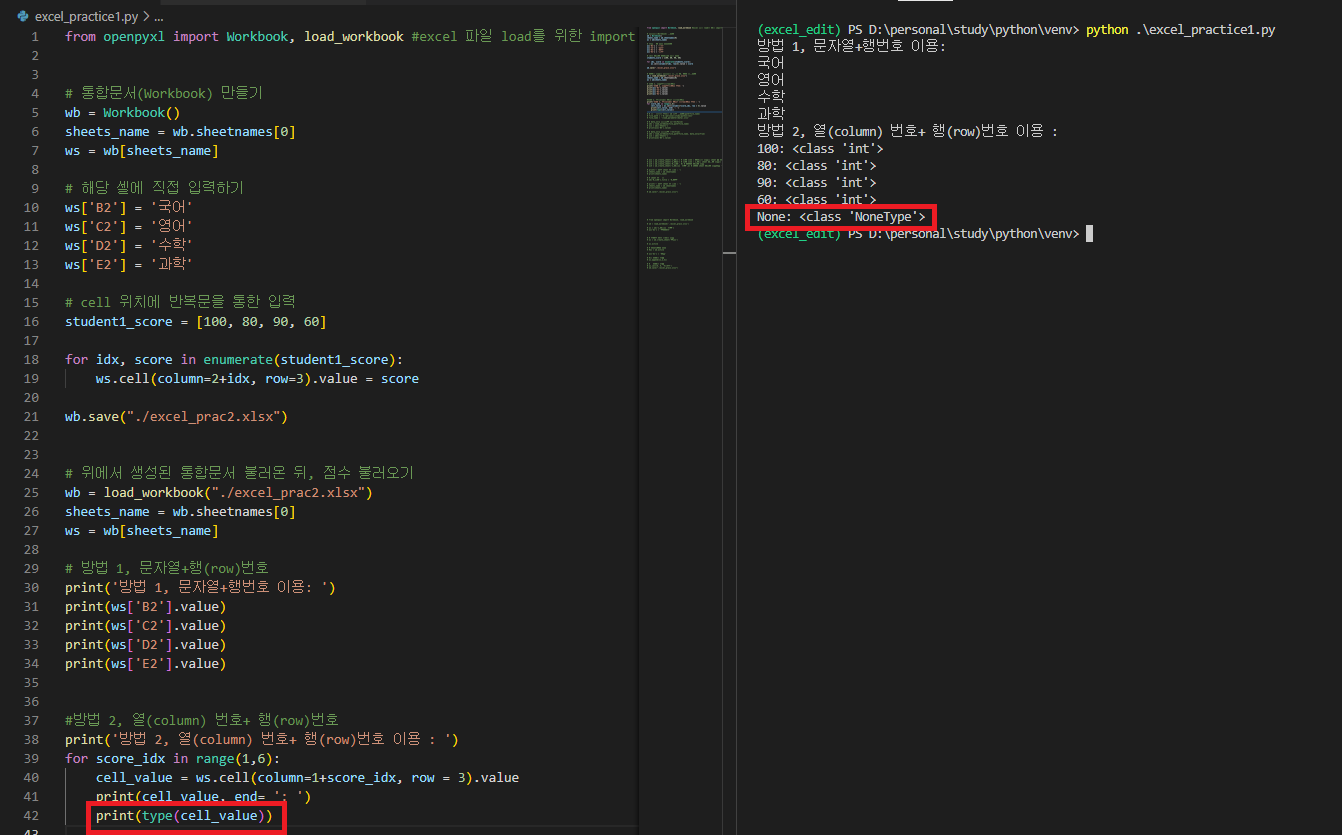
- 좀 더 정확한 확인을 위해 해당 셀의 값이 어떤 자료형인지 확인해보면, 값이 없을 때에는 'NoneType'이 출력되는 것을 확인할 수 있다.
- 해당 결과를 기준으로 학생2(student2)의 점수를 마지막열에 추가해보겠다.
from openpyxl import Workbook, load_workbook #excel 파일 load를 위한 import
# 통합문서(Workbook) 만들기
wb = Workbook()
sheets_name = wb.sheetnames[0]
ws = wb[sheets_name]
# 해당 셀에 직접 입력하기
ws['B2'] = '국어'
ws['C2'] = '영어'
ws['D2'] = '수학'
ws['E2'] = '과학'
# cell 위치에 반복문을 통한 입력
student1_score = [100, 80, 90, 60]
for idx, score in enumerate(student1_score):
ws.cell(column=2+idx, row=3).value = score
wb.save("./excel_prac2.xlsx")
# 위에서 생성된 통합문서 불러온 뒤, 점수 불러오기
wb = load_workbook("./excel_prac2.xlsx")
sheets_name = wb.sheetnames[0]
ws = wb[sheets_name]
# 방법 1, 문자열+행(row)번호
print('방법 1, 문자열+행번호 이용: ')
print(ws['B2'].value)
print(ws['C2'].value)
print(ws['D2'].value)
print(ws['E2'].value)
#방법 2, 열(column) 번호+ 행(row)번호
print('방법 2, 열(column) 번호+ 행(row)번호 이용 : ')
student2_score = [80, 70, 90, 90]
max_row_no = 2
while True:
print(f'max_row_no: {max_row_no}')
if ws.cell(column = 2, row = max_row_no).value == None:
print('hit')
for idx, score in enumerate(student2_score):
print(f'column={2+idx}, row={max_row_no}, {score}')
ws.cell(column=2+idx, row=max_row_no).value = score
max_row_no += 1
break
else: # int 또는 str 이 입력되어 있으면, 다음열 검색
print(ws.cell(column = 2, row = max_row_no).value)
max_row_no += 1
print('\n\n************입력 후, 결과 출력************\n')
for row_no in range(2,max_row_no):
for score_idx1 in range(1,5):
cell_value = ws.cell(column=1+score_idx1, row = row_no).value
print(cell_value, end= ' ')
print('\n')
wb.save("./excel_prac2.xlsx")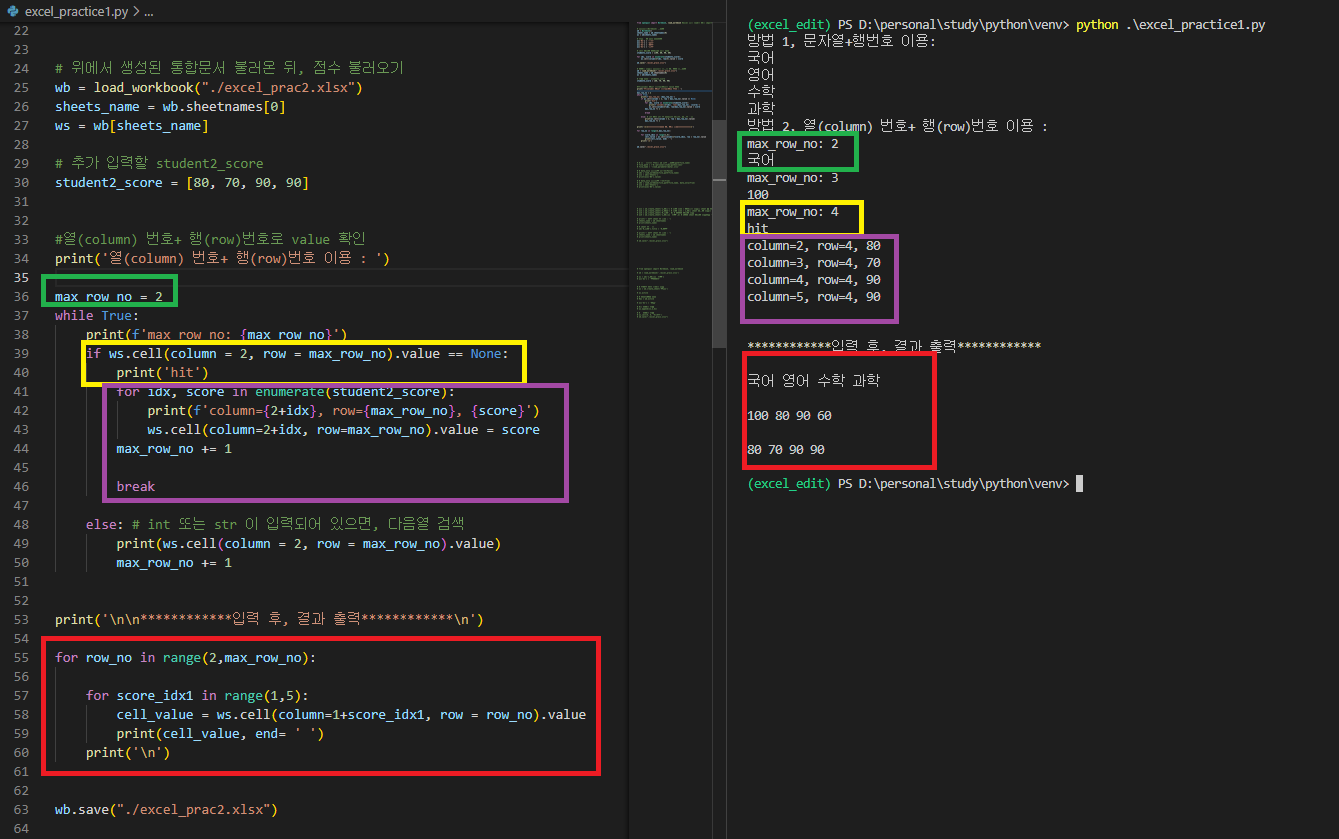
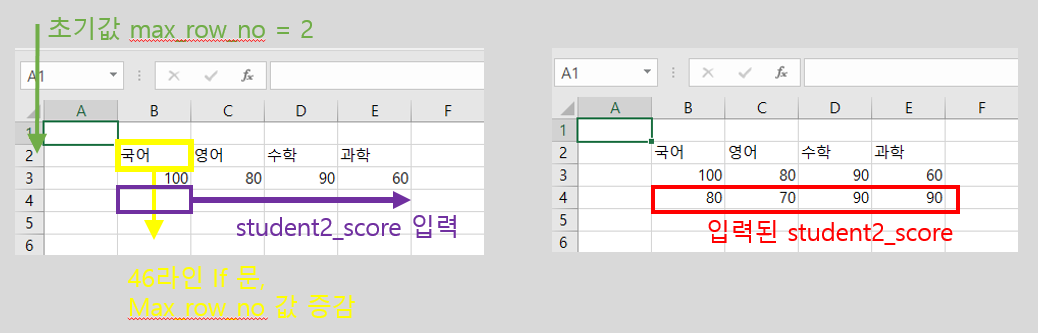
- 각 라인별 진행 사항을 확인해보면, 처음부터 21라인까지는 과목명(2열)과 student1_score(3열)만 입력된 excel 파일을 만들고,
- 25~27 라인을 이용하여 해당 Workbook과 Worksheet를 불러온다.
- 추가할 student2_score를 29라인에 리스트로 작성한 뒤
- 36라인에서 검색할 max_row_no의 초기값(2행)을 설정한다.
- 39라인의 if 조건문을 통해 2열(B열)의 행값을 증가시키며 값이 미입력된(None)을 찾은 뒤,
- 41라인의 for 반복문을 통해 우측으로 열번호를 증가시키며 해당 score를 입력한다.
- 주의 할 사항은 44, 50라인과 같이 while 반복문을 통해 B열의 None 값을 찾을 수 있도록 행번호를 증가시키며 반복문을 수행하는 것과 46라인과 같이 반복문이 종료될 수 있는 break문을 설정해줘야 한다는 것이다.
- 해당 입력을 완료하고 55~60라인을 통해 결과를 확인해보면 정상적으로 값이 추가되었음을 알 수 있다.
- 그런데 매번 이렇게 어렵게 구하지 않아도 열과 행의 최대 값을 확인할 수 있는데, max_row 와 max_column 이다.
- 해당 최대값은 worksheet의 변수값으로 가지고 있다.
from openpyxl import Workbook, load_workbook #excel 파일 load를 위한 import
# 통합문서(Workbook) 만들기
wb = Workbook()
sheets_name = wb.sheetnames[0]
ws = wb[sheets_name]
# 해당 셀에 직접 입력하기
ws['B2'] = '국어'
ws['C2'] = '영어'
ws['D2'] = '수학'
ws['E2'] = '과학'
# cell 위치에 반복문을 통한 입력
student1_score = [100, 80, 90, 60]
for idx, score in enumerate(student1_score):
ws.cell(column=2+idx, row=3).value = score
wb.save("./excel_prac2.xlsx")
# 위에서 생성된 통합문서 불러온 뒤, 점수 불러오기
wb = load_workbook("./excel_prac2.xlsx")
sheets_name = wb.sheetnames[0]
ws = wb[sheets_name]
# 추가 입력할 student2_score
student2_score = [80, 70, 90, 90]
max_row_no = ws.max_row
max_col_no = ws.max_column
print(f'max_row_no : {max_row_no}')
print(f'max_col_no : {max_col_no}')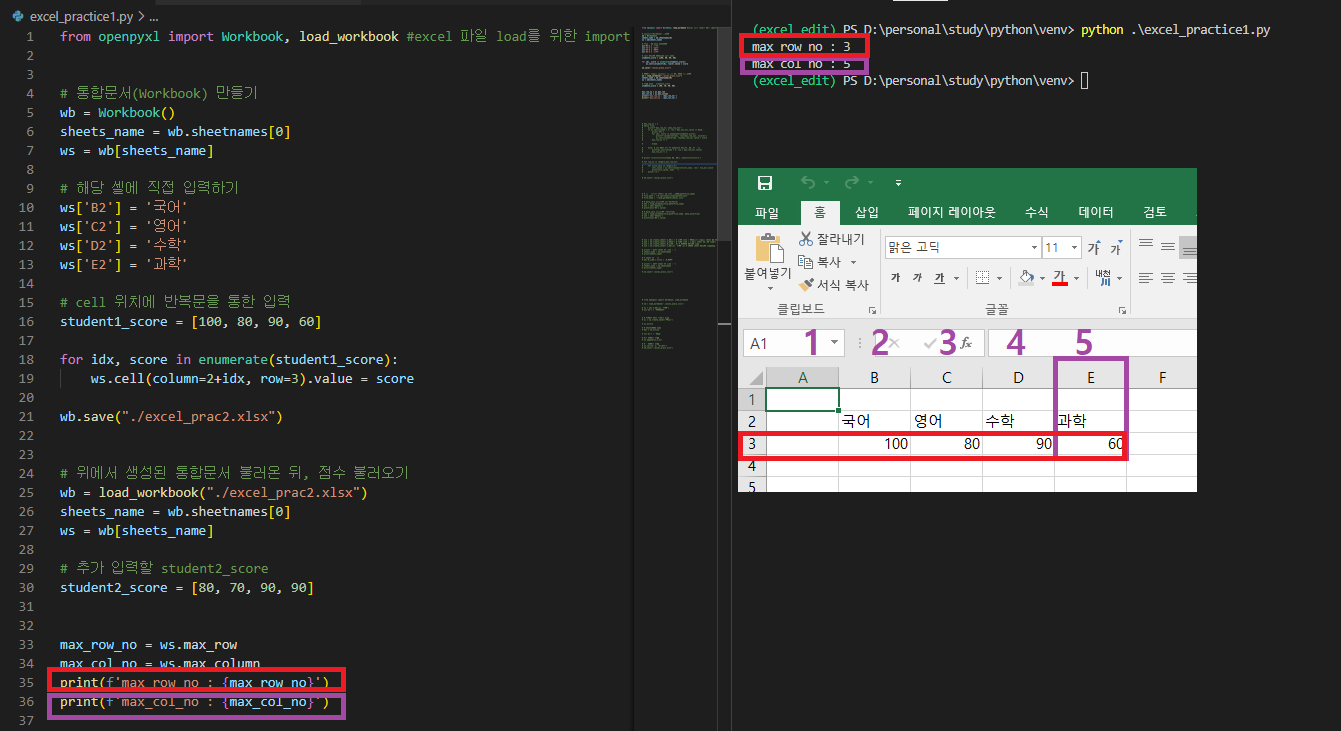
- 처음 빈칸을 찾는, None을 찾는 방법보다. max_row 와 max_column을 쓰면 훨씬 편리하다.
이제 다음 포스팅에서 지금까지 배웠던 파파고(papago) API와 엑셀(Excel)을 연계하는 과정을 마지막으로 openpyxl 라이브러리에 대한 간략한 포스팅을 끝내도록 하겠다.
'Python' 카테고리의 다른 글
| 24. 파이썬 활용 미니프로젝트1(qwerty 분석) (0) | 2023.08.03 |
|---|---|
| 23. 파이썬 엑셀(Excel) 다루기3 - openpyxl with 파파고 (0) | 2023.08.02 |
| 22. 파이썬 엑셀(Excel) 다루기1 - openpyxl (0) | 2023.07.22 |
| 21. 파이썬 네이버 API(Papago) 연동하기2 (0) | 2023.07.19 |
| 20. 파이썬 네이버 API(Papago) 연동하기1 (0) | 2023.07.18 |



