앞선 글에서 봤듯이 우리는 아래의 세가지 궁금증을 해결하기 위해 파이썬의 도움을 받아 분석해볼 예정이다.
(*비교군이 적어 분석 내용이 일부 다를 수도 있다는 것을 염두에 두고 읽어주세요.)
2023.08.03 - [IT 배우기/Python] - 24. 파이썬 활용 미니프로젝트1(qwerty 분석)
24. 파이썬 활용 미니프로젝트1(qwerty 분석)
파이썬으로 어떤 미니프로젝트를 해볼까 라는 고민을 하다 고민의 답을 노트북에서 찾았다. 바로 쿼티(qwerty)라고 부르는 키보드 배열인데, 일반적으로 사용되는 컴퓨터 영문 자판의 첫줄 6글자
to-all-rounder.tistory.com
우리의 궁금증은 아래의 3가지인데,
첫번째, 글속에서의 빈도 수를 통해 해당 배열이 효과적으로 구성되어 있는지
두번째, 글을 입력할 때, 오른손과 왼손을 번갈아 가며 입력하는 구성이 되는지
세번째, 글속에서 사용되는 문자를 쿼티 배열로 입력 할 때 다음 알파벳과의 연속성을 얼마나 차단할 수 있는지이다.
이번글은 첫번째 궁금증인 빈도수와 배열의 관계를 알아볼 예정이다.
해당 궁금증을 해결하기 위해 코리아헤럴드의 신문기사 일부를 발췌했다.
해당 글은 23년 8월 북상 중인 태풍 카눈(http://www.koreaherald.com/view.php?ud=20230801000591)이 우리나라로 다가 오고 있다는 내용이다.
source_text ='''Typhoon Khanun is expected to continue its west-northwest trajectory to Okinawa before stalling for around five to six days in the East China Sea near Shanghai on Thursday. The typhoon’s intensity is expected to stagnate from “very strong” to “strong” and change its direction toward the east and head in a slow northeast direction from the weekend.
With the typhoon’s predicted path prone to more changes in the future, there is also a chance it could approach the Korean Peninsula, according to the KMA.
The meteorological agency added that the typhoon’s predicted path is likely to undergo more significant changes, depending on future mid-range barometric pressure levels. The KMA will quickly communciate any necessary information once the possibility of the typhoon's approaching the Korean Peninsula increases.
While Typhoon Khanun stalls in the East China Sea, the heat wave is expected to persist in Korea. The typhoon will add more heat to the hot and humid air already blowing in from the North Pacific High and the Tibetan anticyclone. It will also bring strong winds toward the southern part of the country and Jeju Island.'''
1. 문자(알파벳) 분리하기
- 실제 코딩을 진행하기 전 string을 list로 변환해 주게 되면 각각의 문자를 기준으로 리스트를 생성할 수 있다.
- 해당 방법을 통해 위의 기사 전문을 문자별(알파벳)로 분리해준다.
text = 'A long long time ago.'
print(text)
split_to_list = list(text)
print(split_to_list)
2. 분석 코드 작성하기
- 11라인 : 최초 문자별 초기값을 0으로 설정한다. 특수문자는 제외하였으며, 아래 반복문에서 예외처리하였다.
- 14라인 : string을 list로 변환하여 문자별로 나누어진 list를 생성한다.
- 19라인 : use_char_count 에 포함되지 않은 Key 값인 특수기호(", ', . 등) 을 예외처리하기 위해 추가
- 20라인 : 원문에 대소문자가 구별되어 있으나, 대문자만으로 치환하여 산출하며 해당 Key 값의 Value를 1증가 시킨다.
# 확인용 소스 텍스트(예제문1)
source_text ='''Typhoon Khanun is expected to continue its west-northwest trajectory to Okinawa before stalling for around five to six days in the East China Sea near Shanghai on Thursday. The typhoon’s intensity is expected to stagnate from “very strong” to “strong” and change its direction toward the east and head in a slow northeast direction from the weekend.
With the typhoon’s predicted path prone to more changes in the future, there is also a chance it could approach the Korean Peninsula, according to the KMA.
The meteorological agency added that the typhoon’s predicted path is likely to undergo more significant changes, depending on future mid-range barometric pressure levels. The KMA will quickly communciate any necessary information once the possibility of the typhoon's approaching the Korean Peninsula increases.
While Typhoon Khanun stalls in the East China Sea, the heat wave is expected to persist in Korea. The typhoon will add more heat to the hot and humid air already blowing in from the North Pacific High and the Tibetan anticyclone. It will also bring strong winds toward the southern part of the country and Jeju Island.'''
# 알파벳별 사용 빈도 확인 초기화
use_char_count = {'A':0, 'B':0, 'C':0, 'D':0, 'E':0, 'F':0, 'G':0, 'H':0, 'I':0, 'J':0, 'K':0, 'L':0, 'M':0, 'N':0, 'O':0, 'P':0, 'Q':0, 'R':0, 'S':0, 'T':0, 'U':0, 'V':0, 'W':0, 'X':0, 'Y':0, 'Z':0 }
# 원문 문자별로 분리하기(string -> list)
split_text_to_list = list(source_text)
for used_char in split_text_to_list:
try: # 알파벳 외 다른 특수문자 등이 입력될 경우, 예외처리
use_char_count[used_char.upper()] = use_char_count[used_char.upper()] + 1
except:
pass
print(use_char_count)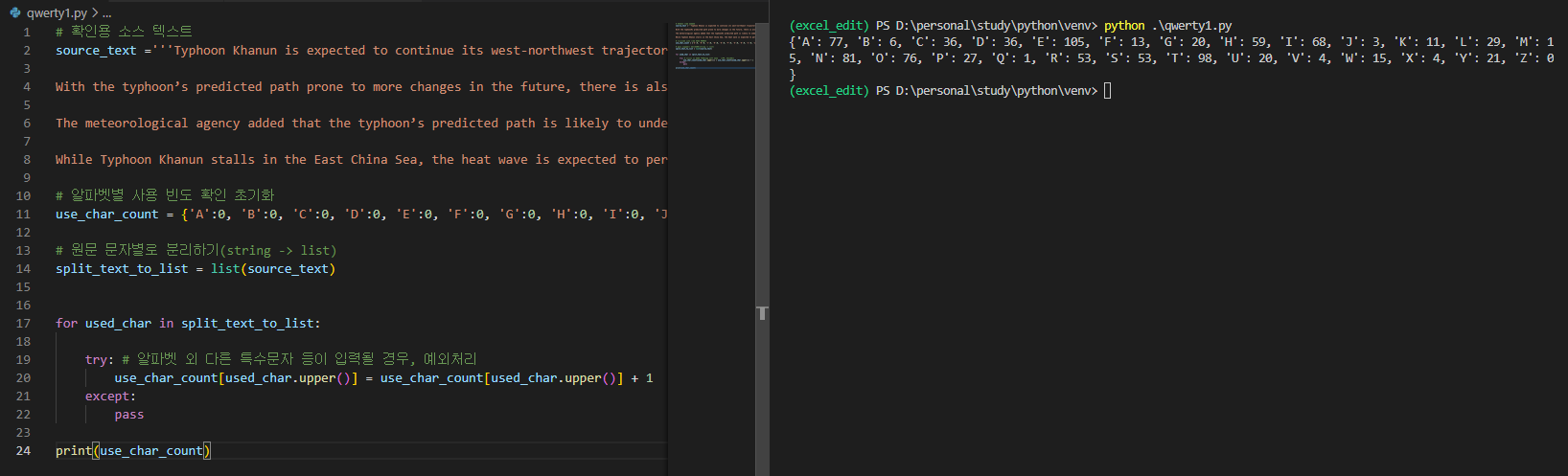
- 단순히 코드 몇 줄만으로 사용 빈도 수를 산출할 수 있다. 문자를 하나씩 일일이 세는 불상사는 파이썬과 함께 없어졌다.
- 해당 결과를 입력하기에 앞서 사용 빈도가 높은 문자부터 정렬을 하면 좀 더 분석이 용이할 거라는 생각이 들어 정렬을 진행하였다.
# 확인용 소스 텍스트(예제문1)
source_text ='''Typhoon Khanun is expected to continue its west-northwest trajectory to Okinawa before stalling for around five to six days in the East China Sea near Shanghai on Thursday. The typhoon’s intensity is expected to stagnate from “very strong” to “strong” and change its direction toward the east and head in a slow northeast direction from the weekend.
With the typhoon’s predicted path prone to more changes in the future, there is also a chance it could approach the Korean Peninsula, according to the KMA.
The meteorological agency added that the typhoon’s predicted path is likely to undergo more significant changes, depending on future mid-range barometric pressure levels. The KMA will quickly communciate any necessary information once the possibility of the typhoon's approaching the Korean Peninsula increases.
While Typhoon Khanun stalls in the East China Sea, the heat wave is expected to persist in Korea. The typhoon will add more heat to the hot and humid air already blowing in from the North Pacific High and the Tibetan anticyclone. It will also bring strong winds toward the southern part of the country and Jeju Island.'''
# 알파벳별 사용 빈도 확인 초기화
use_char_count = {'A':0, 'B':0, 'C':0, 'D':0, 'E':0, 'F':0, 'G':0, 'H':0, 'I':0, 'J':0, 'K':0, 'L':0, 'M':0, 'N':0, 'O':0, 'P':0, 'Q':0, 'R':0, 'S':0, 'T':0, 'U':0, 'V':0, 'W':0, 'X':0, 'Y':0, 'Z':0 }
# 원문 문자별로 분리하기(string -> list)
split_text_to_list = list(source_text)
for used_char in split_text_to_list:
try: # 알파벳 외 다른 특수문자 등이 입력될 경우, 예외처리
use_char_count[used_char.upper()] = use_char_count[used_char.upper()] + 1
except:
pass
print(use_char_count)
# value 값 순서대로 정렬
sorted_use_char_count = sorted(use_char_count.items(), key=lambda x:x[1], reverse=True)
print(sorted_use_char_count)
- 일단 분석을 위해 색상과 횟수별로 표기를 해봤다.
- 키보드에 입력된 횟수를 적었고, 가장 많이 사용된 5개(E, T, N, A, O)는 빨간색, 가장 적게 사용된 5개(Z, Q, J, X, V)는 파란색으로 표기해봤다.
- 쿼티 배열 전 2줄로 구성된 배열의 빈도수를 먼저 확인해보면 아래와 같은데, 너무 오래전 기록이다 보니, 오른손과 왼손을 구별하는 방법을 알 수가 없었다. 단순히 18열 중 가운데인 9번째를 기준으로 나누었는지, 아니면 숫자를 제외한 11번째를 기준으로 나누었는지 알 수 없지만, 전체 921자(평균 35.4자 = 921 / 26) 중에 좌측의 3칸(빨간색 부분)에 234번(평균 38번 = 234 / 3)이 집중되어 있는 것과, 우측 9칸에(파란색 부분) 102번(평균 11.3자 = 102 / 9) 만 보더라도 비효율적으로 배열되어 있음을 알 수 있다.
- 분배를 떠나서도 숫자포함 4열로 배열되는 요즘 배열과 비교할 때, 4열의 경우 타이핑을 위해 손 전체가 움직이는 경우가 없으나, 가로 2열, 18개의 자판을 입력하기 위해서 손 전체가 움직여야 함으로 동선 또한 길어질 것으로 보인다.

- 단순히 보기에도 쿼티 이전의 배열은 효율적인 면에서 떨어지기 때문에 아래에서는 쿼티와 드보락을 기준으로 분석해보겠다.
3. 결과 분석하기1 (쿼티)
- 손가락별로 입력되는 횟수와 라인별로 입력되는 횟수를 비교해봤을 때, 몇가지를 결과를 도출 할 수 있었는데,
1) 최빈 문자(빨간색)가 손가락별로 분산되어 있다는 것과 (최소 문자(파란색)도 분산)
2) 오른손 보다 왼손의 입력이 더 많다는 것지만 비중으로 보면 57:43 으로 크게 한쪽으로 치우쳐 보이지는 않는다는 것.
(콤마와 온점을 추가하면 약소하지만 비중이 조금 더 올라갈 것으로 보이고,
과거 타자기 시절은 아니었지만, 지금은 오른손이 해야할 일이 하나더 있다.
대부분의 오른손 잡이들은 오른손으로 마우스도 사용해야하므로 이정도 비중은 적당해보인다.)
3) 기본적으로 손이 입력 전 대기하는 A라인(3줄)보다 상단(Q라인)의 입력이 더 많다는 것이다.
4) 당연한 얘기이지만 다른 손가락들보다 소지(새끼 손가락)의 비중을 낮춘 것으로 보인다. 아마 shift나 ctrl 같은 기능키를 누르기 위함이 아닐까? 라는 생각을 조금 해본다.

사실 이건 하나의 케이스만을 통해 도출한 결과이다. 검증 데이터가 더 많으면 틀린 결론일 수도 있다.
그래서 정확성을 높히기 위해 하나의 예문을 더 진행해보겠다.
동일한 코리아헤럴드 사이트의 영문 기사로 젊은 세대들이 전화하기를 두려워 하는지를 다룬 글이다.
처음보다 훨씬 긴 문장을 통해 위의 내용을 검증해보겠다.
- 코딩을 이용한 강점은 이런 것이다. 만약 해당 글자를 직접 세어서 자료를 수집한다면, 다시 한번 엄청난 시간과 노력이 투자되어야 하지만, 우리는 source_text를 변경하는 것 만으로 다른 예문을 검토할 수 있다.
# 확인용 소스 텍스트(예제문2)
source_text ='''Title : Why young people have 'call phobia' and how to manage it.
These all-too-familiar symptoms seem to arise when she has to make or receive a phone call, prompting her to avoid speaking on the phone whenever possible.
Phone anxiety, also known as call phobia or telephobia, is a form of social anxiety disorder observed in a growing number of people, particularly among those belonging to the so-called "MZ Generation" -- millennials and Generation Z born between the early 1980s to early 2010s.
"I rarely had opportunities to communicate with people on the phone since childhood," Lee told The Korea Herald. Text messages via chat apps are the predominant way for her to engage in social communications, she added.
Psychology professor Lim Myung-ho from Dankook University said young people have become particularly susceptible to this type of anxiety over the years.
A survey conducted in 2022 by the local research group Embrain, which polled 1,000 individuals, found that the highest percentage of respondents experiencing mental pressure before making phone calls were in their 20s at 43.6 percent, followed by those in their 30s at 36.4 percent. Figures for those in their 40s and 50s were 29.2 percent and 19.6 percent, respectively.
The survey also revealed that approximately 60 percent of respondents in their 20s and 30s preferred texting as their primary mode of communication, with only 14.4 percent of those in their 20s and 16 percent in their 30s opting for phone calls.
When asked for the reason for preferring text, Lee said, "I worry about making mistakes when speaking on the phone. While I can easily revise text messages, I have to be extremely careful not to say anything that might sound impolite or foolish."
For an office worker surnamed Jeon in her 20s, the thought of being on the phone makes her feel uncomfortable, as she feels compelled to respond quickly.
“Unlike text messaging, I don’t have much time to arrange my thoughts during phone calls, which often leads me to stutter or sputter out random things to fill the silence,” she said.
“I have significantly improved my speaking skills by frequently making and receiving phone calls at the office. Yet, I still rely on writing short scripts and anticipating questions to reduce panic during calls,” she added.
Explaining why voice communication induces more stress, professor Lim points out that texting is a less emotionally charged format than speaking, as the voice carries one's emotions.
“Many people in their 20s and 30s struggle when dealing with direct and spontaneous emotions conveyed through talking on the phone because they are more accustomed to communicating through text messages,” he said.
The daunting nature of phone conversations can also be attributed to the communication being enacted solely through talking, without other social cues such as body language and facial expressions, he explained.
As a way to combat phone anxiety, Lim calls for acknowledging one's insecurities and gradually exposing oneself to phone calls in a variety of social settings over a long period of time.
“I recommend having conversations on the phone with people you are close to regularly and preparing scripts beforehand if calling is too stressful,” Lim said, adding, “Phone anxiety should be better dealt with, especially in the workplace, where effective communication skills are of utmost importance.”
Furthermore, for alleviating phone anxiety, Shin You-ah, a speech director at U Speech, a private speech improvement institution, offers both mental and physical treatment.
“Firstly, creating a new mindset is important. If you feel nervous about making phone calls, you need to stay calm and eliminate fear by recognizing that phone calls will not have serious repercussions,” Shin said.
“We also help students practice diaphragmatic breathing, through which they not only calm their mind but also deepen and stabilize their voice,” Shin said.
She further stated, “In the face of unexpected calls, they should answer and politely ask for time to call back, organizing their thoughts and reducing anxiety in the meantime.”
Both Shin and Lim emphasized the importance of listening to and becoming aware of one's own voice as a way to manage the phobia.'''
# 알파벳별 사용 빈도 확인 초기화
use_char_count = {'A':0, 'B':0, 'C':0, 'D':0, 'E':0, 'F':0, 'G':0, 'H':0, 'I':0, 'J':0, 'K':0, 'L':0, 'M':0, 'N':0, 'O':0, 'P':0, 'Q':0, 'R':0, 'S':0, 'T':0, 'U':0, 'V':0, 'W':0, 'X':0, 'Y':0, 'Z':0 }
# 원문 문자별로 분리하기(string -> list)
split_text_to_list = list(source_text)
for used_char in split_text_to_list:
try: # 알파벳 외 다른 특수문자 등이 입력될 경우, 예외처리
use_char_count[used_char.upper()] = use_char_count[used_char.upper()] + 1
except:
pass
print(use_char_count)
# value 값 순서대로 정렬
sorted_use_char_count = sorted(use_char_count.items(), key=lambda x:x[1], reverse=True)
print(sorted_use_char_count)
두번째 원문으로 위의 결과를 비교해보면
1) 최빈 문자(빨간색)가 손가락별로 분산되어 있는가? (최소 문자(파란색)도 분산)
: 일치
최빈 문자 5개가 E, T, O, I, N 으로 위의 A 대신 I가 추가되었으나, 최빈 문자가 손가락별로 분산되어 있는 것은 동일하다. 추가로 위의 결과에서는 I가 6번째 최빈 문자였고, 현재 원문에서는 A가 6번째 최빈 문자이다.
(*최빈 문자 6개를 뽑았으면 결과가 같으며, A, E, T, N, I, O 6개의 최빈 문자를 입력하는 손가락은 각각 다르며, 우연일 수도 있지만, 왼손 3개, 오른손 3개이다. 이런것까지 계산된 결과라면 소름.....)
최소 문자 5개는 J, Q, Z, X, K로 위의 결과에서 V대신 K가 추가 되었으나, 손가락별 분산은 되어 있으나, 최소 문자의 의미는 크게 없는 것 같다.
2) 오른손과 왼손의 입력 비중이 적당한가?
: 일치
첫번째 결과가 57 대 43 에서 두번째 결과가 55.5 대 44.5 로 큰 차이가 나지 않는다.
3) A라인(3줄)보다 상단(Q라인)의 입력이 더 많은가?
: 일치
Q라인(2줄)의 입력이 A라인(3줄)보다 더 빈도가 높다.
4) 소지(새끼 손가락)의 비중이 다른 손가락 대비 작은가?
: 일치
왼손의 경우 소지와 약지간의 큰 차이가 나지 않으나, 오른손의 경우 약지 대비 소지의 비중이 작다.
단 두번의 경우일 뿐이지만, 쿼티의 배열도 분산적인 측면에서 나쁘지 않은 결과가 나온 것 같다.
4. 결과 분석하기 2(드보락)
위의 결과를 바탕으로 쿼티가 마냥 타이핑 속도를 낮추기 위해 설계된 건 아니라는 느낌이 들었을 것이다.
그럼 공학적으로 설계된 드보락 자판의 결과와 비교를 해보면 어떨까?
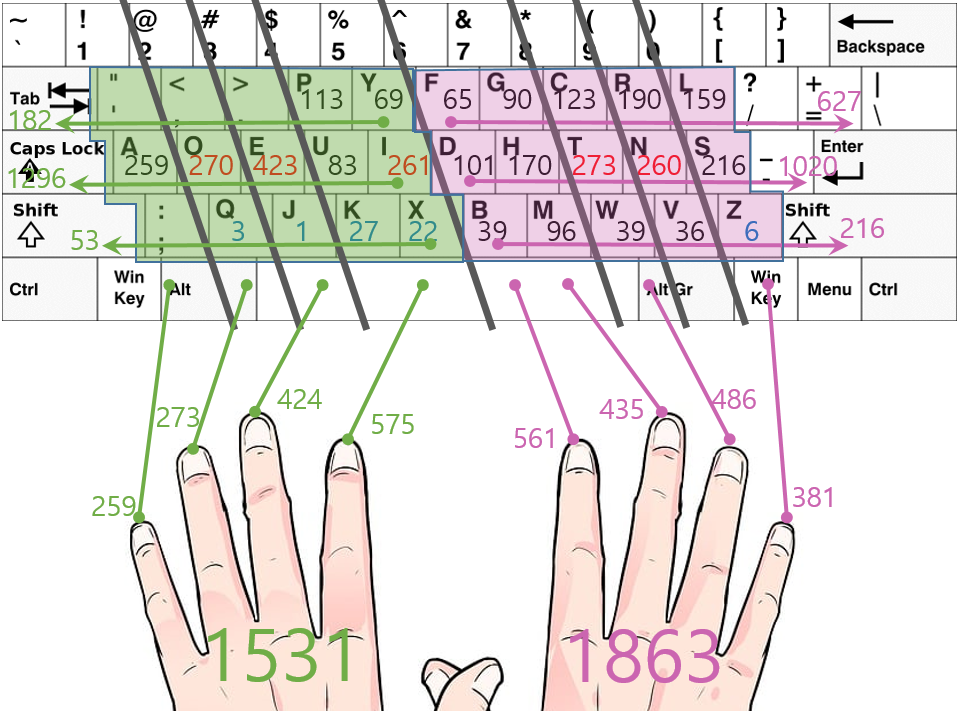
확실히 쿼티보다 깔끔한 결과가 보이는 듯한 느낌의 배열이다.
쿼티와 비교를 해보면,
1) 쿼티의 최빈 문자들은 Q라인(2열)에 집중되었던 것에 비해, 드보락은 A라인(3열)에 빈도수가 높은 키들이 집중되어 있다.
2) 빈도수가 낮은 키들은 가장 아래열에 집중된 것으로 볼 때, 손가락간의 이동범위가 더 적고 조밀하게 집중되어 있다.
3)그리고 쿼티는 왼손의 빈도가 더 높았지만, 드보락은 오른손의 빈도가 더 높다.
그런데 신기하게도 1885 : 1509 에서 1531 : 1863으로 맞바뀐 비율까지 비슷하다.
표로 정리해보면 아래와 같다.
| 쿼티 배열 | 드보락 배열 |
 |
 |
| 2열(Q라인)에 빈도수가 높음(약 51%) | 3열(A라인)에 빈도수가 높음(약 68%) |
| 왼손의 입력 비율이 더 높음 (55.5 : 44.5) | 오른손의 입력 비율이 더 높음 (45.2 : 54.8) |
| - 빈도수가 낮은 키는 손가락별로는 분산되어 있으나, 효율적이지는 않아 보임. 드보락과 달리, 기본 대기를 하는 J와 K의 위치가 빈도수가 낮은 키가 위치해 아쉬움 - 손가락별 비중(왼손 소지 -> 오른손 소지 방향) 8 : 8: 19: 20 : 20: 8: 13: 3 오른손 중지의 비중이 다소 적음 |
- 빈도수가 낮은 키는 4열(Q라인)에 집중됨 - 손가락별 비중(왼손 소지 -> 오른손 소지 방향) 8 : 8 : 12 : 17: 17 : 13 : 14 : 11 쿼티와 비교 시 훨씬 고르게 분포 되어 있음 |
| 대중화가 되다 보니 단축키가 사용하기 좋음. ex) Ctrl + C, Ctrl + V 같은 복사, 붙여넣기, 잘라내기, 전체 선택 등의 한손 사용이 편리함 |
일반적인 단축키를 사용하기 위해 양손을 사용해야함 |
| 대부분의 오른손 잡이가 마우스를 사용함으로 마우스와 혼용하기 좋음. | 오른손의 빈도가 높아 쿼티 대비 마우스를 사용하기에 불편함. |
| 라인별 비중 (%) : 소수점 1자리 반올림 - 2열(Q라인) : 51% - 3열(A라인) : 32% (기본 자리) - 4열(Z라인) : 17% |
라인별 비중 (%) : 소수점 1자리 반올림 - 2열("라인) : 24% - 3열(A라인) : 68% (기본 자리) - 4열(;라인) : 8% |
쿼티의 배열도 고민한 흔적이 있어보였지만, 마우스와 단축키를 제외하고 타이핑만 다룬다면 드보락 배열이 더 좋아보인다.
하지만, 마우스와 단축키라는 쿼티만의 장점이 약간의 불편함이 있더라도 쿼티를 계속 사용할 수 있는 강점이 되고 있다.
아마 시대적인 기회를 잡은 쿼티를 기준으로 단축키 등이 보편화되었기 때문일 것이다.(쿼티 효과 또는 선점 효과)
다음 포스팅에서 사용 빈도수를 제외한 남은 2개의 궁금증을 검증해보겠다.
'Python' 카테고리의 다른 글
| 27. 파이썬 활용 미니프로젝트1(qwerty 분석3) (0) | 2023.08.07 |
|---|---|
| 26. 파이썬 활용 미니프로젝트1(qwerty 분석3) (0) | 2023.08.05 |
| 24. 파이썬 활용 미니프로젝트1(qwerty 분석) (0) | 2023.08.03 |
| 23. 파이썬 엑셀(Excel) 다루기3 - openpyxl with 파파고 (0) | 2023.08.02 |
| 22. 파이썬 엑셀(Excel) 다루기2 - openpyxl (0) | 2023.07.25 |



